A little while back I discussed
embedded attributes in documents that provide intelligence to support features like semantic search, security, rights and even management of
workflow outside of the firewall. Aside from the gamesmanship of Microsoft pushing its new Office Open XML format onto the standards train to
compete with the ODF format of Open Office, this new Microsoft format is playing catchup in its support for XML. The three key dimensions enabling document intelligence are covered: open access to content; XML document metadata storage; dynamic attribute storage for forms and process state.
The
15 year old PDF format has had the ability to embed attributes in files since the format was first created, partially based as I understand it on Adobe's work on
Postscript and some over the shoulder looks at the Aldus
Tagged Image File Format (TIFF) - Aldus eventually 'merged' with Adobe in 1994. TIFF originally contained metatags to enable device independent storage and display of scanned documents, and any raster images. Initially simple tags described physical attributes of the image like width, height, resolution, color depth, compression and so on.
The
TIFF specification was designed to be extensible, enabling new tags to be added to meet the requirements of emerging capabilities or individual vendors. This is exactly what intelligent documents need - a mechanism for recording any type of attributes inside the file. In PDF 1.4, the format recognized the need for XML support for multiple dimensions, not just to describe the document's 'physical' properties, but also to enable it to be more easily edited outside of its primary Acrobat authoring application and to enable storage of dynamic attributes from forms. According to
Classic Planet PDF:
XML support. Under pressure to extend PDF to include XML markup, Adobe has made changes in three areas. First, Acrobat forms can now be set up to capture data as tagged XML, as well as HTML and Adobe's FDF format. Second, Adobe is introducing a new metadata architecture to PDF, one based on an RDF-compliant DTD. Metadata can be attached both at the document and object level, and the DTD can be extended, opening up interesting possibilities for defining and embedding metadata other than the basic set supported in Acrobat 5. Third, Adobe has defined a way to embed structure into PDF. Called "Tagged PDF," it is a set of conventions for marking structural elements within the file.
This multi-dimensional support for XML inside the document is part of modern PDF's power and ability to support a range of security, rights and workflow capabilities offline. Microsoft on the other hand has not got to this level yet. Of course, the MS Office products have supported metadata attributes to describe the document for several versions (title, author, etc), extending this to enable custom attributes to be added more recently. The problem has been that non-Microsoft applications, including document repositories, have struggled to be able to reuse this information without accessing an application like MS Word through its OLE interface. In a Java world this requires some reading of the proprietary Office format, something error-prone and generally poorly supported. As for XML representation of the displayable content, this was still a sideline capability in the last version of Office.
In Office 2007 Microsoft will provide a common XML-based format that will be used by default for all of the Office products,
Open XML. According to Microsoft:
By default, documents created in the next release of Microsoft Office products will be based on new, XML-based file formats. Distinct from the binary-based file format that has been a mainstay of past Microsoft Office releases, the new Office XML Formats are compact, robust file formats that enable better data integration between documents and back-end systems. An open, royalty-free file format specification maximizes interoperability in a heterogeneous environment, and enables any technology provider to integrate Microsoft Office documents into their solutions.
This will have the following advantages:
- Compact file format. Documents are automatically compressed—up to 75 percent smaller in some cases.
- Improved damaged file recovery. Modular data storage enables files to be opened even if a component within the file is damaged—a chart or table, for example.
- Safer documents. Embedded code—for example, OLE objects or Microsoft Visual Basic for Applications code—is stored in a separate section within the file, so it can be easily identified for special processing. IT Administrators can block the documents that contain unwanted macros or controls, making documents safer for users when they are opened.
- Easier integration. Developers have direct access to specific contents within the file, like charts, comments, and document metadata.
- Transparency and improved information security. Documents can be shared confidentially because personally identifiable information and business sensitive information—user names, comments, tracked changes, file paths—can be easily identified and removed.
- Compatibility. By installing a simple update, users of Microsoft Office 2000, Microsoft Office XP, and Office 2003 Editions can open, edit, and save documents in one of the Office XML Formats.
In reality, the Open XML format is a bunch of XML files that represent each component of the Office document, alongside binary objects like images, all zipped into a single package. This has obvious advantages both from the simplicity for developers to get at the appropriate information for reading and editing outside of the core applications, as well as the compression that zip can offer. In addition, there are none of the hassles associated with embedding binary objects in XML - images and multimedia objects can remain in their standard formats, just packaged within the zip.
This covers two of the main facets required for intelligence: open, editable content and accessible document metadata. Now Office documents be edited and assembled outside of the MS Word, Excel, Powerpoint, etc applications, enabling automation around the format, for example for document generation from backend business data. Also, repositories can read the document metadata by just examining an XML file.
The storage of document metadata in XML within the Open XML package will initally be leveraged when storing documents to Sharepoint. Users will be presented with a document information panel in Word, to enable easy capture of identifying or semantic information for the document. On storing the document to Sharepoint, these attributes entered into the form in Word are read by Sharepoint to update its structured 'index' metadata used for classifying and searching documents. This is a round-trip process - on removing a document from Sharepoint, the document attributes stored in Open XML will be set based on the current Sharepoint index metadata, ensuring that the document is up to date and can be identified offline. Due to the open format, other vendors' repositories can (and should) do the same.
Transfer of document to repository metadata is simple, powerful integration that could be useful to many organizations when tracking documents. At the same time, it presents issues when dealing with published, finalized documents - do you or don't you update the metadata in a document that should otherwise be locked down, when retrieving it from a records repository?
The final dimension of document intelligence, capture and storage of dynamic metadata, as Adobe uses in PDF for forms and worflow state, could be considered to be covered by extending this approach, coupled with Microsoft's
InfoPath 2007:
Microsoft Office InfoPath 2007 is a Windows-based application for creating rich, dynamic forms that teams and organizations can use to gather, share, and reuse information—leading to improved collaboration and decision-making throughout your organization.
InfoPath is used to design the document information panel that will be presented to users in Word 2007, enabling complex forms to be used to capture document metadata. If the document is central to a workflow process, the process related attributes could also be captured here. These are transferred back to Sharepoint when submitted back to the system, enabling the Microsoft workflow to deliver the document to the next user appropriate to the information entered. This is much the same as Adobe does with Livecycle. To complete the picture, pure InfoPath forms can be delivered by workflow, email, web or Sharepoint Portal, enabling information collection outside of a document centric world. In Microsoft's world, forms and documents are separate packages that can be used independently or combined as required.
There has been much discussion over the relationship between Microsoft
Open XML and ODF, and their interchange. I believe that although Microsoft sees the threat from Open Office, but as much emphasis is being placed on getting Office to a state where it can compete with higher end users and their preference for Adobe (the threat is
evident to Adobe it seems). Microsoft is finally catching up with Adobe in its ability to provide document intelligence within its Office documents, enabling offline classification, document workflow management and forms data capture. Coupled with
Microsoft's ECM strategy with Sharepoint and workflow, Office 2007 will be a good stepping stone to effective document and business process management in every organization over the next few years. All vendors in the space need to adapt fast to stay ahead of the game, while leveraging the power that both Microsoft and Adobe offer with their products.
Technorati tags: intelligent documents ODF PDF Open XML Microsoft Office 2007



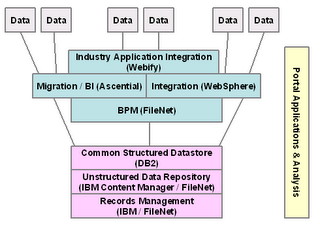 This morning's announcement by IBM that it intends to acquire FileNet was a little surprising. Many observers had been suggesting that FileNet would drop soon, but I don't believe anyone guessed to IBM. My outsider view was that there was far too much overlap in their offerings for this to make sense from a technology viewpoint.
This morning's announcement by IBM that it intends to acquire FileNet was a little surprising. Many observers had been suggesting that FileNet would drop soon, but I don't believe anyone guessed to IBM. My outsider view was that there was far too much overlap in their offerings for this to make sense from a technology viewpoint.